Everyone who experienced somewhat statistical learning theory knows how important a feature can be. Feature engineering is a game changer process/implementation to create even more features in addition to existing ones by aiming performance increase. However, we sometimes don't want to use some of those features, not completely removing but just temporarily ignoring them. Particularly, while training neural networks, we want to drop out some nodes randomly in each batch because, in order to avoid overfitting, we don't want the model to rely on some dominant ones. This is a regularization technique called Dropout and is first introduced in 2012 with this paper. In a high level presentation, you can imagine the training of a house pricing model, but you hide the features like, number of bedrooms, location or the building age in each iteration from the model randomly.
 In Regularization I trust - Source
In Regularization I trust - Source
Check the below example, it sets the dropout keep probability 0.6, 0.4, and 0.6 for each layer respectively on the right-hand side.
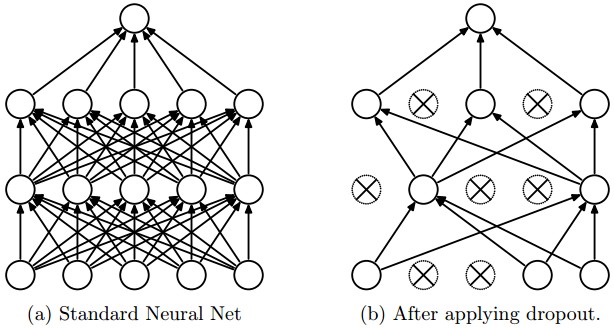 Taken from the paper "Dropout: A Simple Way to Prevent Neural Networks from Overfitting"
Taken from the paper "Dropout: A Simple Way to Prevent Neural Networks from Overfitting"
Dropout is very popular and useful in many Deep Learning Architecture especially Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN). I'll test how well they perform with dropout in a sequence text classification problem on the famous IMDB Movie Review dataset. The dataset has 25,000 movie reviews and their labels as positive or negative, the networks will be trained to predict these labels.
Because every model, every problem is different and need different approach, this post should only provide an insight just for one of them. The post doesn't intend to generalize anything about aforementioned networks or techniques. Let's get more about the networks first.
Networks
CNN is mostly used for image classifications and its design follows vision processing in living organisms. It's also great as an autoencoder. It's one of the rare networks that more than 2 hidden layers can significantly increase the performance. It also has cool 3D layers unlike the other's boring layers. I think the most important thing about CNN is its design to look for the pattern, the sequence in other words, it only looks for banana, doesn't care much where the banana is located in the image.
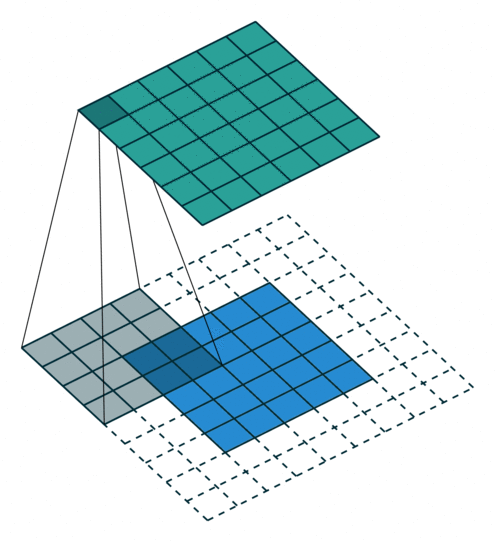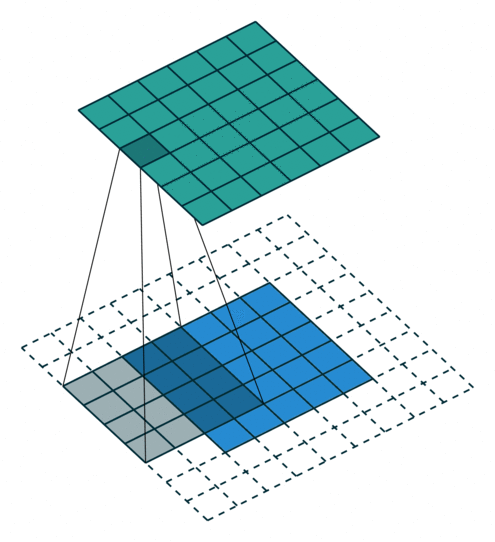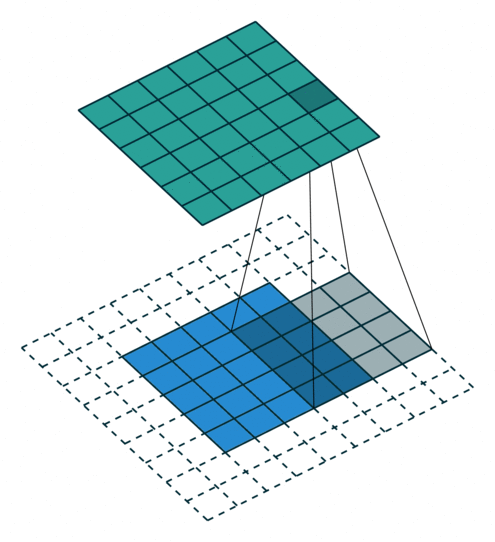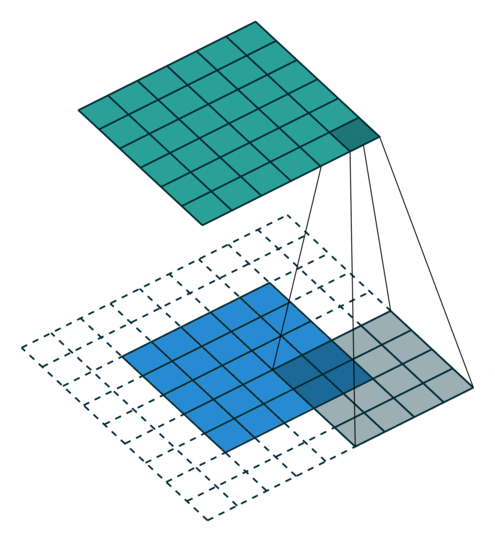 Arbitrary Padding, No Strides in a CNN - Source
Arbitrary Padding, No Strides in a CNN - Source
RNN is the network with memory. With its LSTM cells, it's great for the applications such as speech recognition, handwriting recognition or sentiment analysis. It's also different than conventional methods with its sequence classification capability. It looks for the pattern, the meaning. Same words or characters may create completely different output by changing the arrangement just like the human language.
Basically, both look for the pattern.
 Do you see the resemblance?
Do you see the resemblance?
That's why CNN may also be great at text classification so I want to compare against RNN on the same data of the same problem, I can also test the dropout effect in this comparison.
The code below shows the exact networks in the comparison for the ones who are also interested in the coding part.
As you can see, I implemented dropout only once in both networks for simplicity.
Results
It looks like the models converge in the epoch somewhere between 6-15, after 15. epoch models start overfitting so I'll only consider epoch 6-15 while interpreting the results. Even though RNN looks performing slightly better, it's hard to mention about any significant difference between the networks. Notice that the accuracy range is 0.7-0.85, not 0.0-1.0 as default.
You can also see that RNN and CNN response differently to dropout keep probability values. The accuracy for RNN almost constantly increases while the dropout keep probability is decreasing, whereas CNN behaves the opposite way or no significant changing at all. Frankly, I wasn't expecting any accuracy increment for small dropout keep probability values such as 0.1 and 0.2, but RNN performs especially better for the values less than 0.4. Having said that, that slight difference in accuracy between models is getting bigger while the dropout keep probability decreasing after 0.4.
Let's look at the training time comparison now.
RNN can't keep the same performance in training time comparison and let CNN wins here by far. On average, CNN is 1.68 times faster than RNN. For this problem, it'd be a good choice to go with CNN unless ~1% improvement in accuracy is important. RNN's slowness may be a huge drawback considering the fine tuning.
It's also worth to mention that smaller keep probability values make training speed slower or not change much in general. Shouldn't dropout make things faster since it's dropping out some features, meaning less computation? Although it decreases the computation amount by removing some nodes from the network, it chooses which nodes to keep randomly, so there is random sampling in each iteration, repeatedly. Apparently, the random sampling here takes more time than the saving time by those calculations. This is a great paper proposing how to handle this issue partially. It's definitely worth to read.
Moreover, dropout doesn't affect training times much in CNN comparing to RNN. This may need further research, but I believe the reason behind this is in "R" in RNN. RNN's internal memory to process arbitrary sequences of inputs may make it less sensitive to fewer computations in dropout layer.
To sum up, as I said before, it'd be misleading to generalize networks behaviours by looking only one problem. For this problem, with this network configurations, CNN is the winner with its super speed as opposed to RNN's slightly better accuracy in my opinion.
By the way, for those who say "why not both?", there is a completely different problem that Google uses both networks to address. This is an excellent research combining these awesome networks for an image descriptor model.
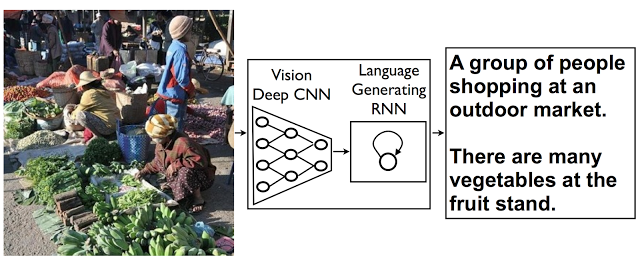 The model combines a vision CNN with a language-generating RNN so it can take in an image and generate a fitting natural-language caption. - Source
The model combines a vision CNN with a language-generating RNN so it can take in an image and generate a fitting natural-language caption. - Source
You can also see the entire result data by clicking below if you want to examine or analyse further.
Epilogue
I hope this post provides you some insight about how CNN and RNN work and the dropout technique affects their behaviours.
You can see the repository here for the project details.
Please reach me for any questions, comments, suggestions or just to say Hi!
Lastly, share it if you like this project;